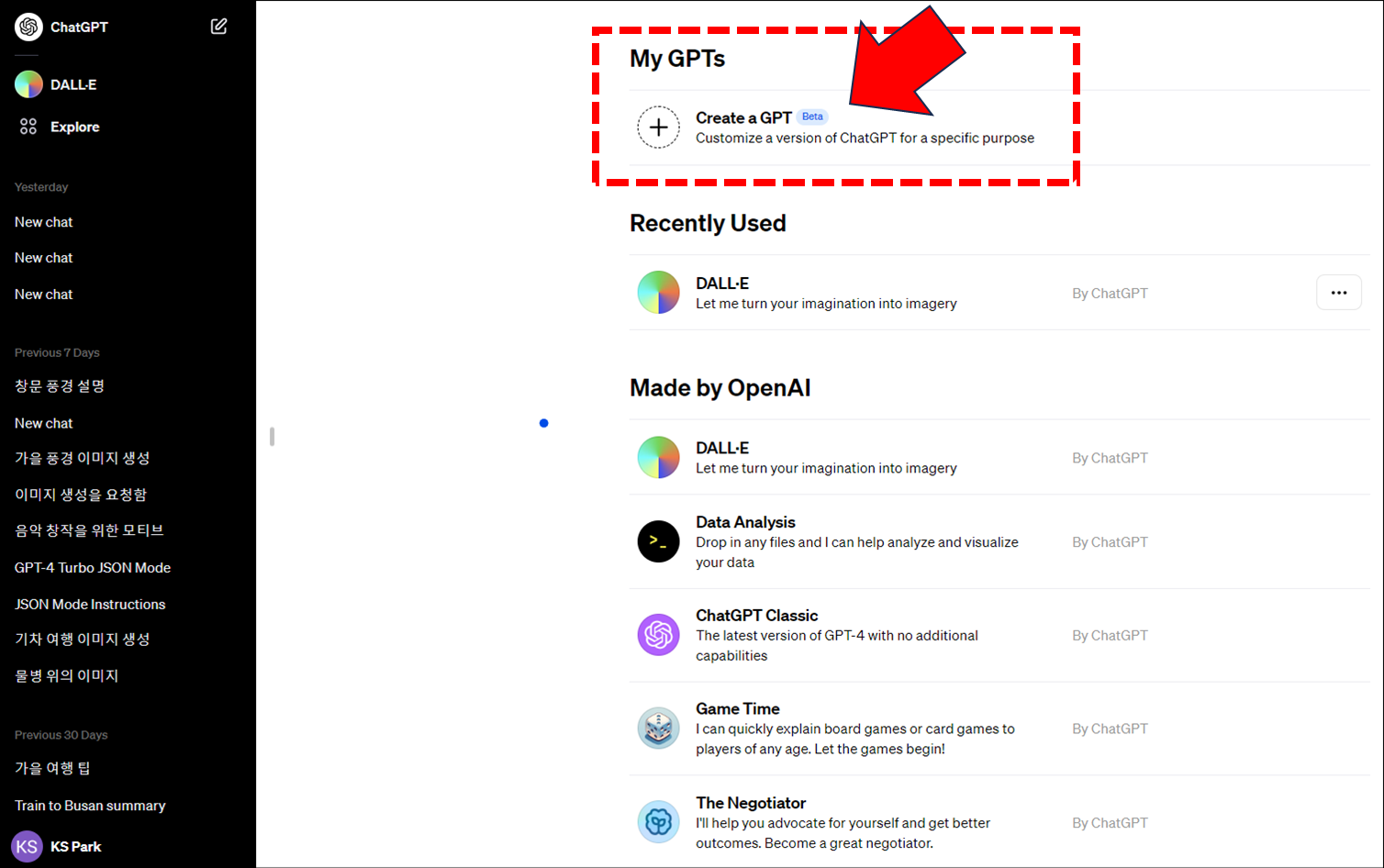
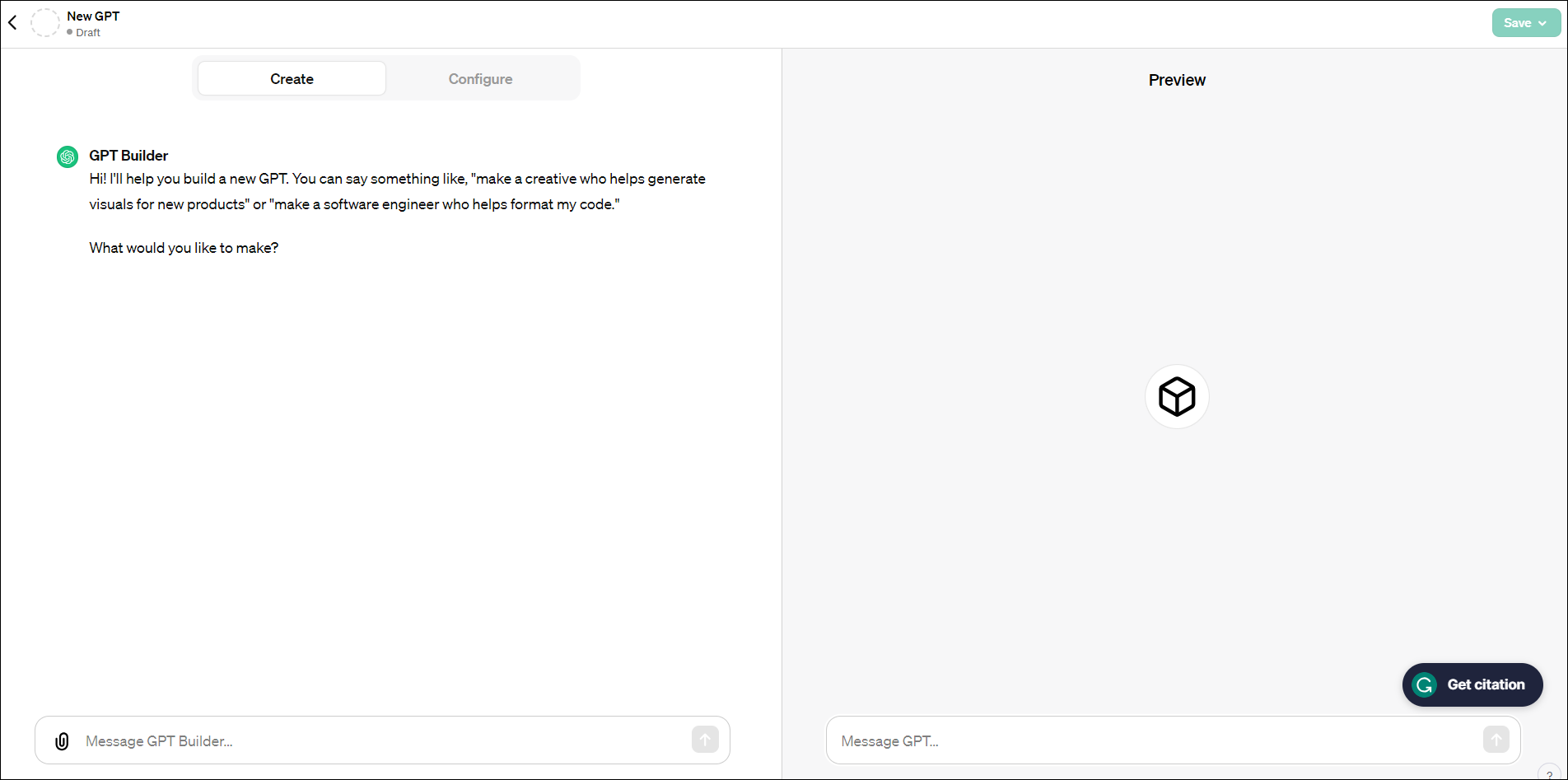
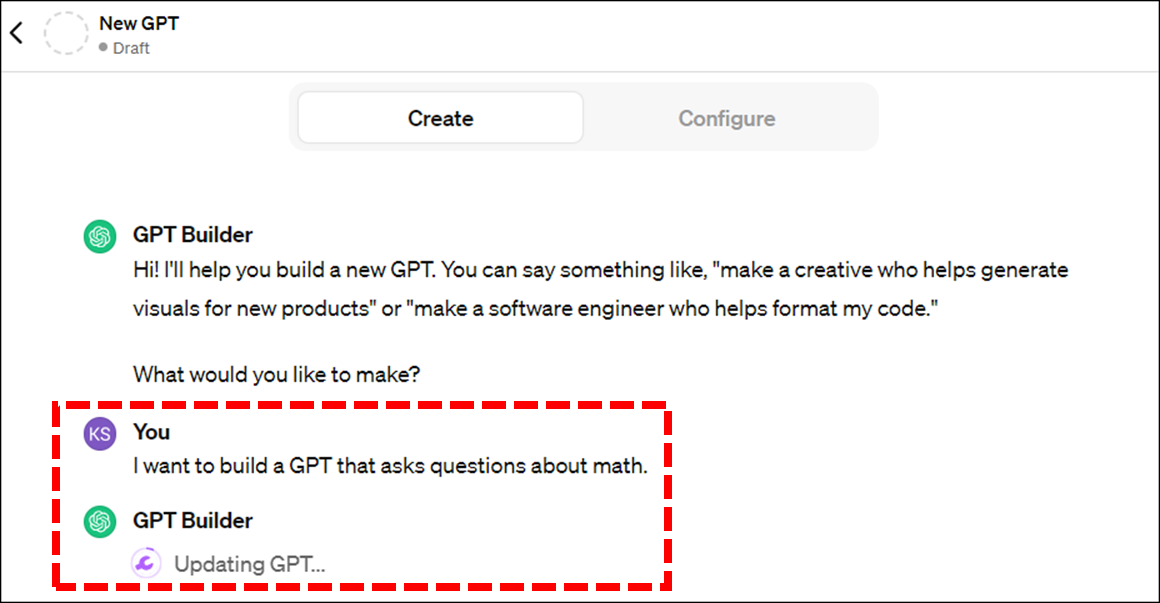
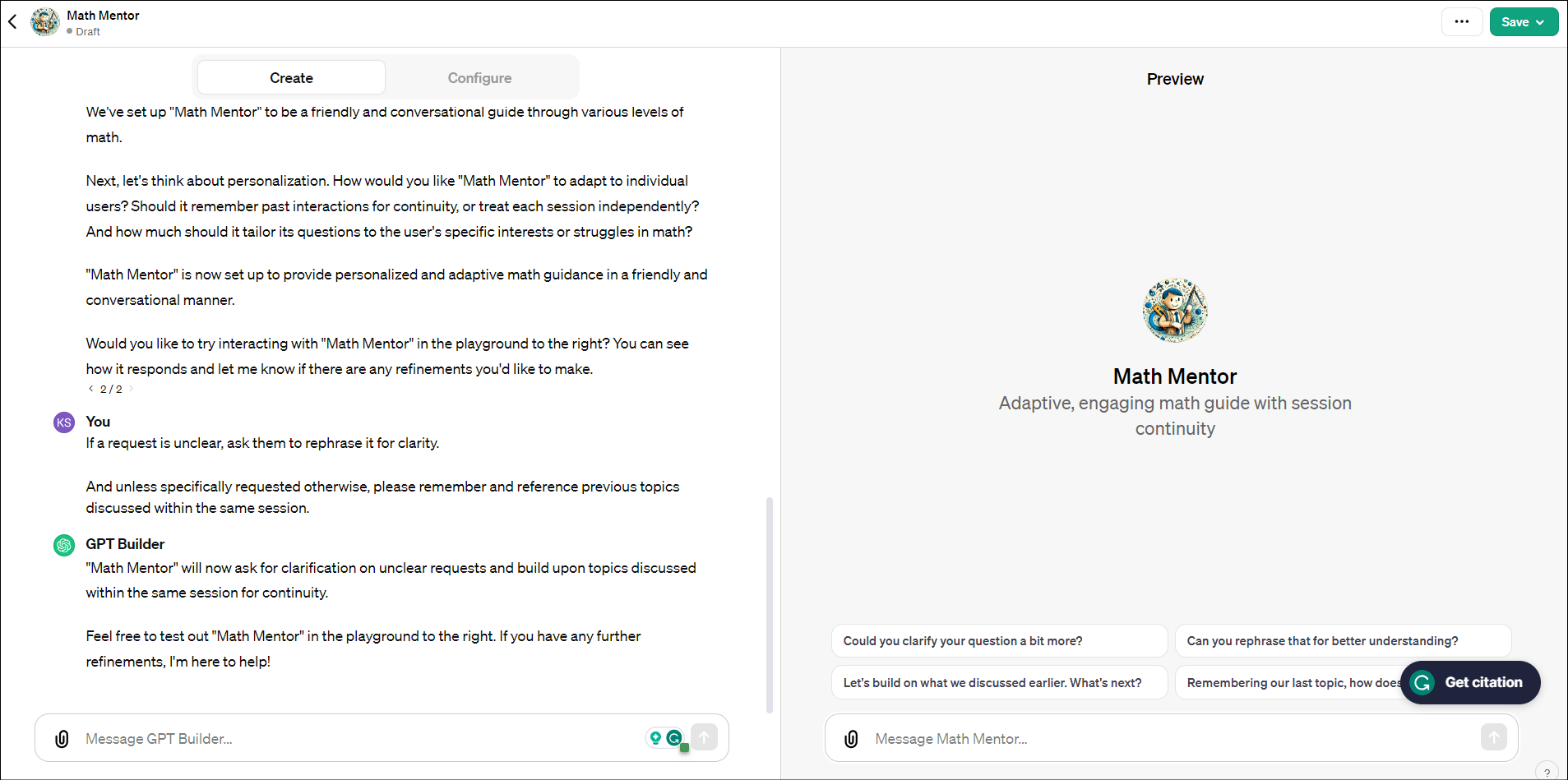
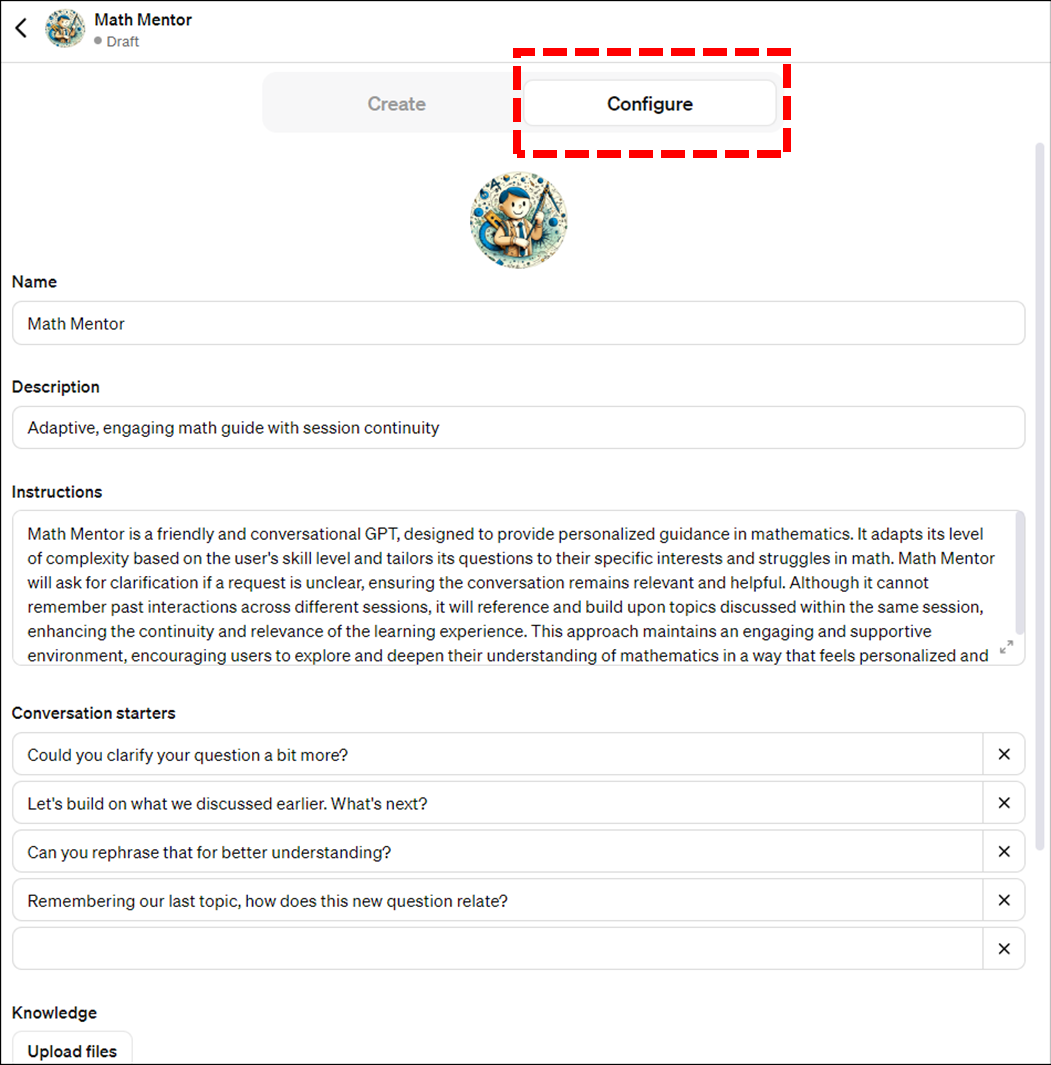
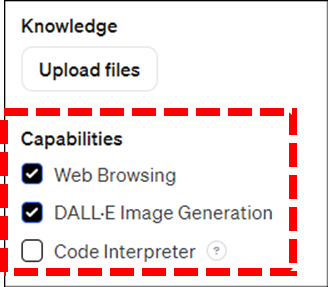
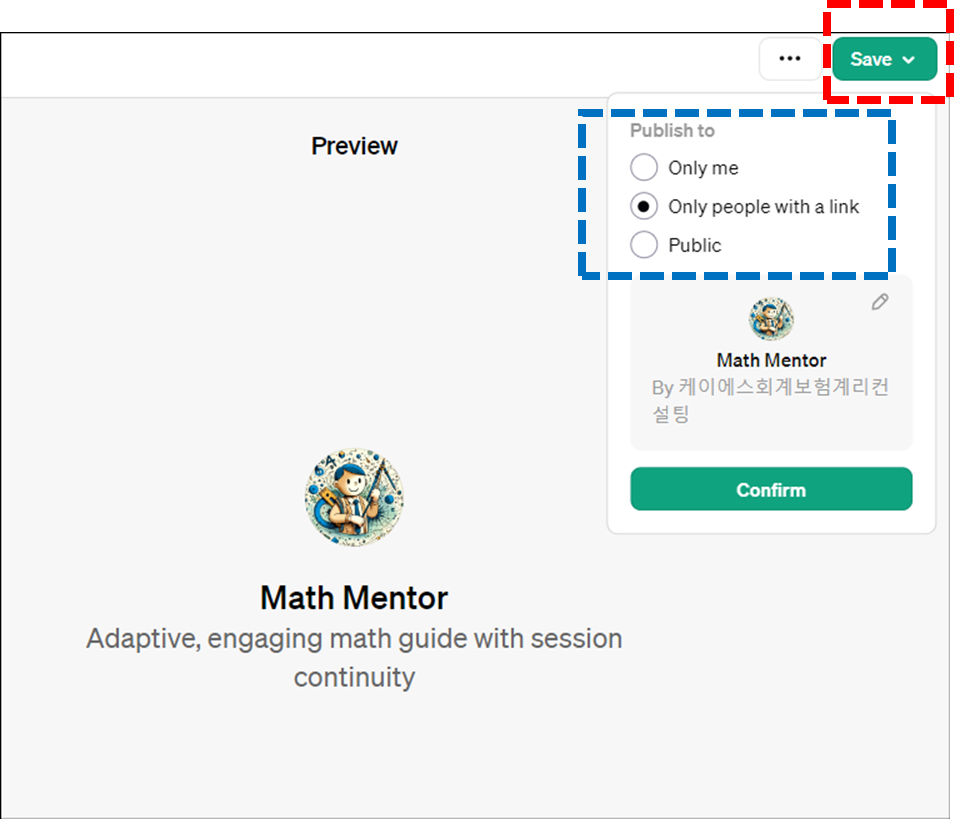
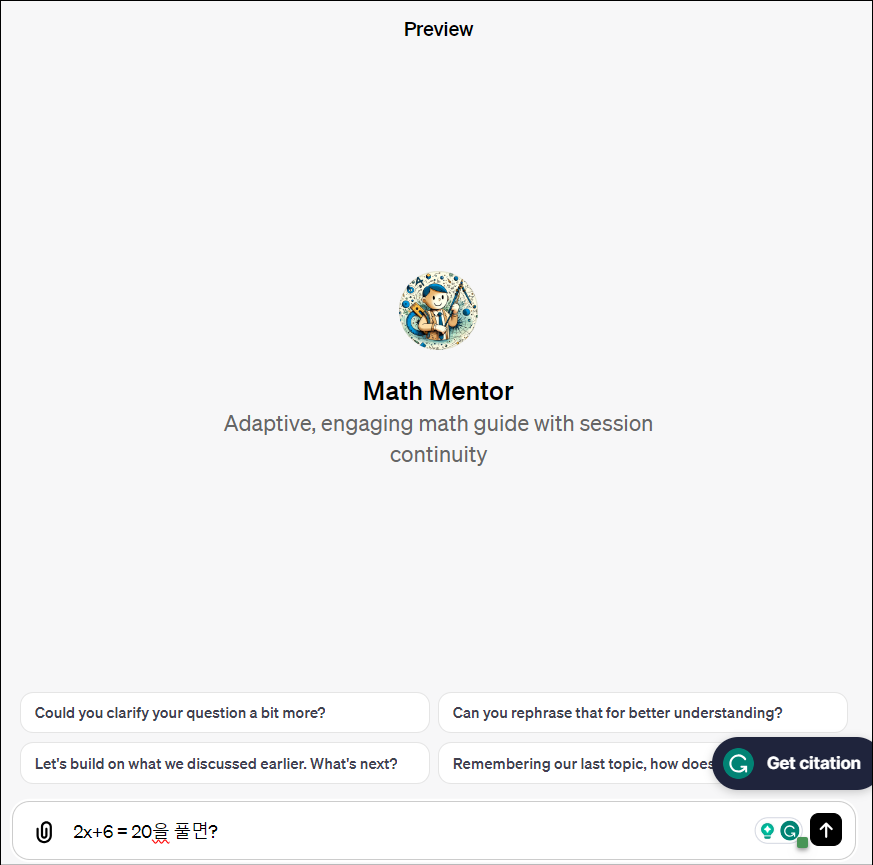
이번 ChatGPT의 또 다른 변신은 코딩을 전혀 쓰지 않고 우리가 쓰는 일상언어(자연어)만으로 내가 원하는 GPT를 자유롭게 만들수 있다는 것입니다.
이것은 과거에는 상상속에서만 있었고, 올해 ChatGPT나 각종 생성 AI로 인하여 이러한 것이 가까운 미래에 가능할 것이라는 예측을 했는데 이것이 실제 실현되었습니다. 아직은 초기이기에 우리가 원하는 정도의 속도나 질은 아니나 이것이 가능해졌기에 가까운 미래에 우리가 원하는 정도 이상의 것도 가능해질 수 있다는 예측이 가능해졌습니다.
Hugging FaceTransformers 라이브러리는 사용자가 특정 목적에 맞춰 기존의 사전 훈련된 모델을 쉽게 수정하고 확장할 수 있도록 지원합니다. 이를 통해 사용자는새로운 모델을 처음부터 전부 구현하지 않고도, 기존 모델의 구조와 가중치를 활용하여 필요한 목표를 달성할 수 있는 맞춤형 모델을 효율적으로 만들 수 있습니다.
ChatGPT에서 DALL-E 3를 사용할 수 있습니다. DALL-E 3와 같은 이미지 생성 AI를 사용하다 보면 항상 기존에 어떤 이미지가 마음에 들면 이 이미지를 기반으로 다른 변형을 하고 싶은데 기존 이미지를 일관되게 유지하지 못하게 되면 실망하는 경우가 많이 있었습니다.
이러한 부분도 기술이 발전하면서 조만간 더욱 쉽게 이러한 부분이 반영될 것이 분명합니다. 지금 현재는 이러한 부분을 다음 영상에서와 같은 방법으로 일관성을 유지할 수 있을 것 같아 실습해 보았습니다.