
📌 목차
- DeepSeek-VL2 소개
- DeepSeek-VL2 모델의 핵심 기술
- DeepSeek-VL2 사용 방법
- DeepSeek-VL2 데모 실습(Hugging Face Space)
- 비교 실습
- 동영상
💡 실습과 관련 내용은 2025.2월 현재로 사용하는 시점에 따라 성능은 달라질 수 있습니다.
1. DeepSeek-VL2 소개
최근 멀티모달 AI의 발전 속도가 빠르게 증가하면서, 이미지와 텍스트를 동시에 처리하는 Vision-Language 모델(VLM)에 대한 관심이 높아지고 있습니다.
DeepSeek 팀에서 발표한 DeepSeek-VL2는 이러한 흐름을 반영하여 개발된 Mixture-of-Experts(MoE) 기반의 대규모 Vision-Language 모델입니다.
DeepSeek-VL2는 기존 DeepSeek-VL 모델을 개선한 버전으로,
✔ 이미지-텍스트 질의응답 (Visual Question Answering, VQA)
✔ 광학 문자 인식 (Optical Character Recognition, OCR)
✔ 문서, 표, 차트 이해 (Document/Table/Chart Understanding)
✔ 시각적 지시 이해 및 응답 (Visual Grounding)
등 다양한 멀티모달 태스크에서 뛰어난 성능을 보입니다.
DeepSeek-VL2 모델 구성
DeepSeek-VL2는 다음과 같은 세 가지 버전으로 제공됩니다.
| 모델명 | 활성화된 파라미터(억 개) | 주요 특징 |
| DeepSeek-VL2-Tiny | 10 | 경량화 모델 |
| DeepSeek-VL2-Small | 28 | 밸런스 모델 |
| DeepSeek-VL2 | 45 | 고성능 모델 |
특히, DeepSeek-VL2는 기존 공개된 MoE 기반 VLM 모델들과 비교해 유사한 또는 더 적은 활성화된 파라미터를 사용하면서도 뛰어난 성능을 보인다는 점에서 주목받고 있습니다.
2. DeepSeek-VL2 모델의 핵심 기술
🔹 Mixture-of-Experts (MoE) 구조
DeepSeek-VL2는 Mixture-of-Experts(MoE) 아키텍처를 채택하여, 특정 입력에 따라 활성화되는 전문가 네트워크를 조합하는 방식으로 작동합니다.
이를 통해, 모델이 더 적은 파라미터를 사용하면서도 대규모 모델 수준의 성능을 유지할 수 있습니다.
🔹 멀티모달 이해 및 고급 추론 능력
DeepSeek-VL2는 단순한 이미지-텍스트 매칭을 넘어,
✔ 문서 내 논리적 관계 파악
✔ 표와 차트에서 수치 및 의미 분석
✔ 손글씨 인식 (Bad Handwriting OCR)
✔ 연속적인 이미지 비교 및 판단
과 같은 고급 비주얼-언어 이해 능력을 갖추고 있습니다.
이러한 특성 덕분에, 자율주행, 의료 데이터 분석, 금융 데이터 시각화 등 다양한 분야에서 활용될 수 있습니다.
[참고] Mixture-of-Experts(MoE) 기반의 대규모 Vision-Language 모델이란?
📌 1. 기존 AI 모델과의 차이점
기존의 AI 모델은 하나의 거대한 신경망(Neural Network)을 사용하여 모든 입력 데이터를 처리합니다.
즉, 모든 작업에 대해 같은 모델이 전체 네트워크를 사용하므로,
- 연산량이 많아 GPU/TPU 성능이 좋아야 하고
- 모든 입력에 대해 동일한 수준의 계산이 적용되므로 비효율적인 경우가 많습니다.
💡 하지만 Mixture-of-Experts(MoE) 방식은 다릅니다!
📌 2. MoE 방식이란?
Mixture-of-Experts (MoE) 는 **"여러 개의 전문가(Experts) 네트워크를 조합하여 학습하는 방법"**입니다.
즉, 하나의 거대한 모델이 아닌 여러 개의 작은 전문가 모델(Experts)들이 존재하며,
각 입력 데이터에 따라 가장 적절한 전문가 모델이 선택되어 실행됩니다.
✔ 하나의 모델이 모든 문제를 해결하는 것이 아니라,
✔ 입력된 데이터의 특성에 따라 가장 적절한 전문가(Expert) 모델을 선택하여 계산하는 방식입니다.
예를 들어,
📌 Vision-Language 모델(VLM)에서 MoE가 적용되는 방식
- **OCR(광학 문자 인식)**이 필요한 경우: OCR 전문가 네트워크 활성화
- 이미지 속 객체 분석이 필요한 경우: 이미지 분석 전문가 네트워크 활성화
- 표와 차트 해석이 필요한 경우: 표/차트 분석 전문가 네트워크 활성화
💡 즉, 필요한 부분만 연산을 수행하므로 연산량을 줄일 수 있으며, 최적의 성능을 발휘할 수 있습니다.
3. DeepSeek-VL2 사용 방법
DeepSeek-VL2 모델을 직접 실행하는 방법은 두 가지가 있습니다.
✅ 1) Hugging Face 데모 페이지 활용 (권장)
DeepSeek-VL2는 모델 크기(32GB)가 커서, Google Colab에서 실행하기 어렵습니다.
따라서, Hugging Face에서 제공하는 웹 데모 페이지를 직접 활용하는 것이 가장 좋은 방법입니다.
👉 🔗 DeepSeek-VL2-Small Demo (Hugging Face)
https://huggingface.co/spaces/deepseek-ai/deepseek-vl2-small
Chat with DeepSeek-VL2-small - a Hugging Face Space by deepseek-ai
Running on Zero
huggingface.co
📌 사용 방법:
- 위 링크를 클릭하여 Hugging Face 데모 페이지로 이동
- "Upload Image" 버튼을 클릭하여 테스트할 이미지를 업로드
- 텍스트 입력창에 질문 입력 (예: "What is written in this image?")
- "Run" 버튼 클릭 → 모델이 이미지를 분석하고 답변 생성
✔ Colab 환경 없이도 바로 실행 가능
✔ 무료로 사용할 수 있으며, 강력한 GPU를 필요로 하지 않음
✅ 2) Hugging Face API를 활용한 실행 (Google Colab)
Hugging Face API를 활용하면, Colab에서 직접 실행하지 않고도 DeepSeek-VL2 모델을 사용할 수 있습니다.
📌 Google Colab에서 실행하는 코드:
# 1. 필수 라이브러리 설치
!pip install --upgrade requests
import os
import requests
import json
from google.colab import userdata
from google.colab import files
# 2. Hugging Face Token 불러오기 (Google Colab Secrets 활용)
HF_TOKEN = userdata.get("HuggingFace_Token")
if HF_TOKEN:
print("✅ Hugging Face Token Loaded Successfully!")
os.environ["HUGGINGFACEHUB_API_TOKEN"] = HF_TOKEN
else:
print("❌ Hugging Face Token Not Found! Please check the Colab secrets.")
# 3. Hugging Face API URL 설정
API_URL = "https://api-inference.huggingface.co/models/deepseek-ai/deepseek-vl2-small"
headers = {"Authorization": f"Bearer {HF_TOKEN}"}
# 4. 사용자 노트북에서 이미지 업로드
print("📤 이미지 파일을 업로드하세요...")
uploaded = files.upload()
# 업로드된 파일 확인 후 첫 번째 파일 선택
image_path = list(uploaded.keys())[0]
print(f"📂 업로드된 파일: {image_path}")
# 5. Hugging Face API로 이미지 분석 요청
with open(image_path, "rb") as image_file:
image_data = image_file.read()
response = requests.post(API_URL, headers=headers, files={"file": image_data})
# 6. 결과 출력
if response.status_code == 200:
result = response.json()
print("📝 AI의 응답:", json.dumps(result, indent=4, ensure_ascii=False))
else:
print("❌ API 호출 실패:", response.text)
⚠ 주의:
현재 Hugging Face API는 10GB 이상 모델을 실행할 수 없기 때문에, DeepSeek-VL2 API는 사용할 수 없습니다.
따라서, 일반 무료 사용자들은 Hugging Face 데모 페이지를 활용하는 것이 가장 현실적인 방법입니다.
✅ 3) DeepSeek V3나 ChatGPT 모두 가능
현재는 사실 ChatGPT의 Multimodal이 더 편리하고 강력. 그러나, 후발주자의 발전은 결국 소비자의 효용 증대로 연결된다는 사실!!!
4. DeepSeek-VL2 데모 실습(Hugging Face Space)
(1) 실습 손글씨 데이터
- 영문
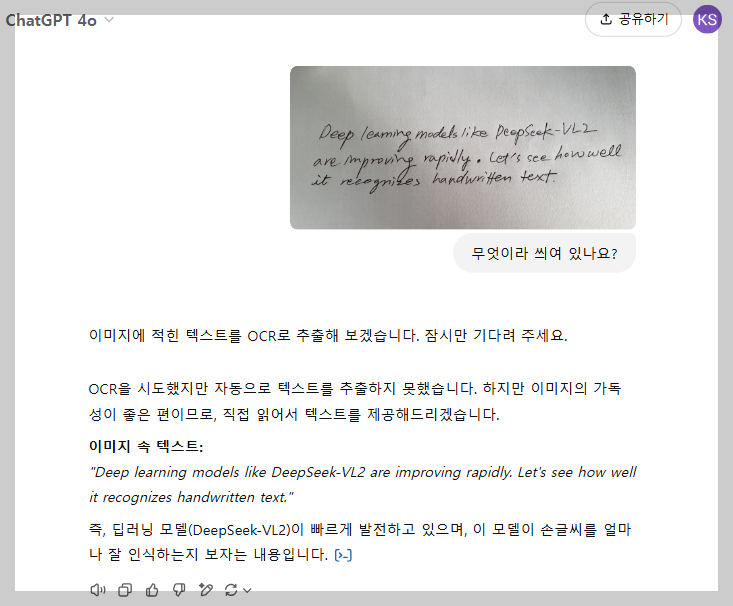
"Deep learning models like DeepSeek-VL2 are improving rapidly. Let's see how well it recognizes handwritten text."

- 한글
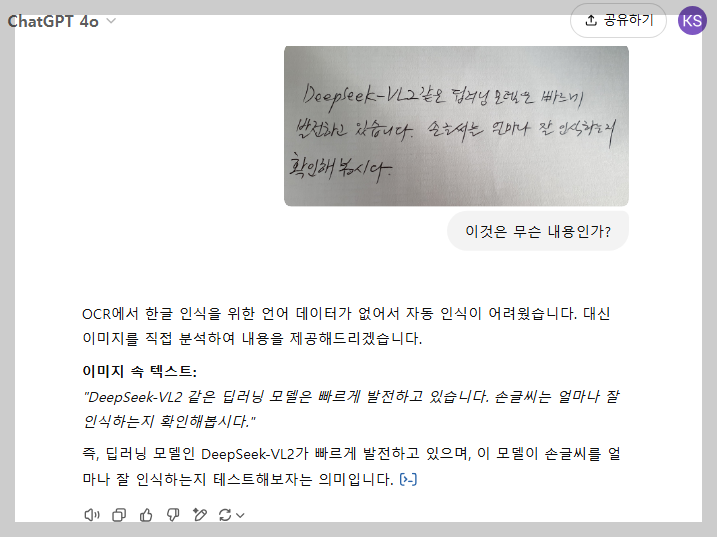
"DeepSeek-VL2 같은 딥러닝 모델은 빠르게 발전하고 있습니다. 손글씨를 얼마나 잘 인식하는지 확인해 봅시다."

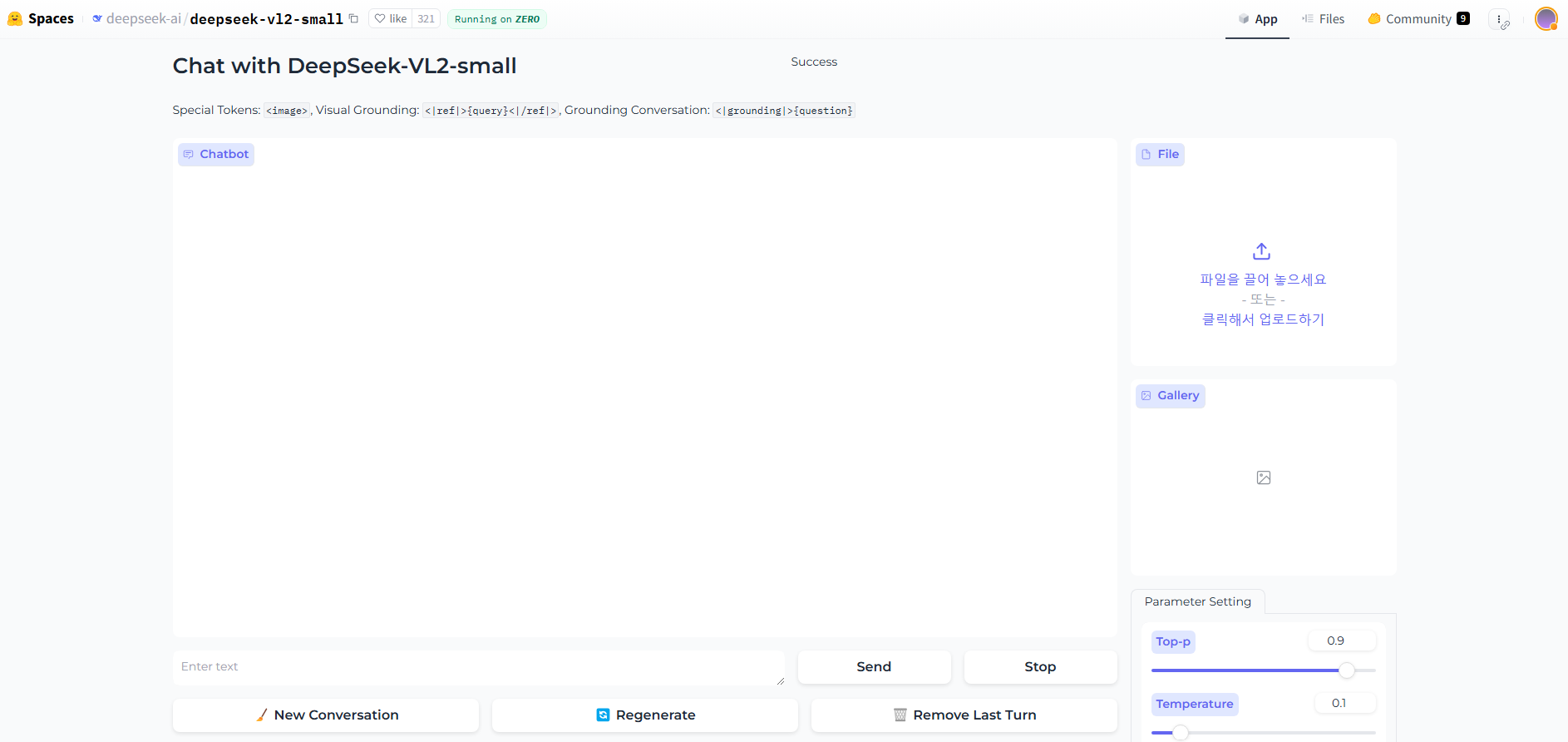
(2) Hugging Face Space Demo
- 데모 화면: Chat with DeepSeek-VL2-small
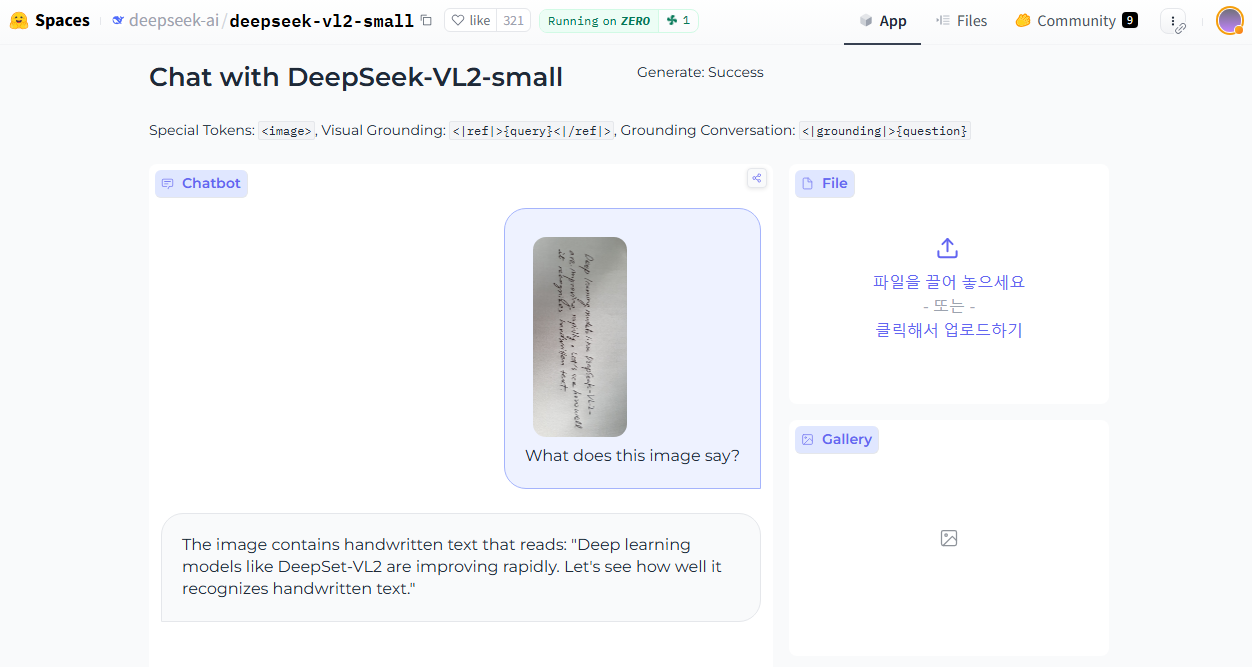
(3) 실습
- 영문 데이터: "Deep learning models like DeepSeek-VL2 are improving rapidly. Let's see how well it recognizes handwritten text."
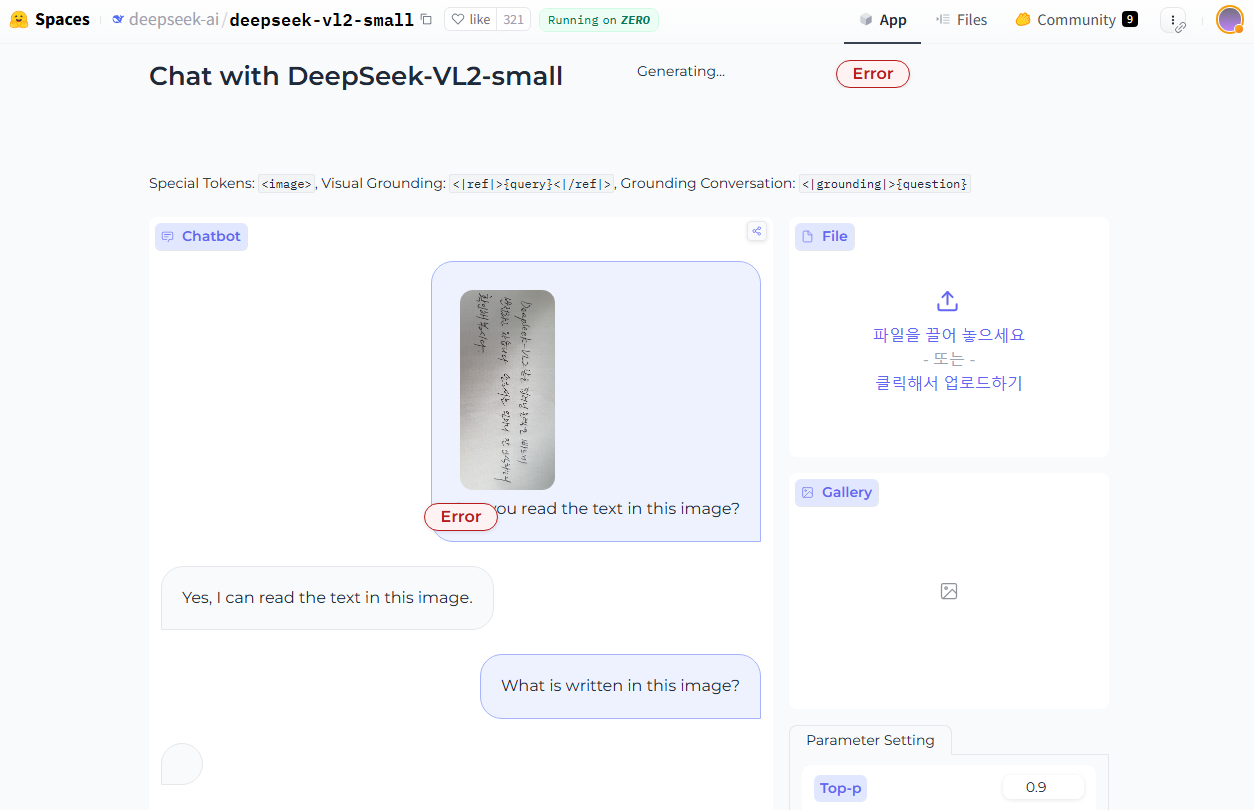
- 한글 데이터: "DeepSeek-VL2 같은 딥러닝 모델은 빠르게 발전하고 있습니다. 손글씨를 얼마나 잘 인식하는지 확인해 봅시다."
- 한글은 현재 처리를 못하고 있습니다 ~
DeepSeek-VL2는 차세대 Vision-Language 모델 중 가장 강력한 MoE 기반 모델 중 하나로 평가됩니다.
5. 비교 실습
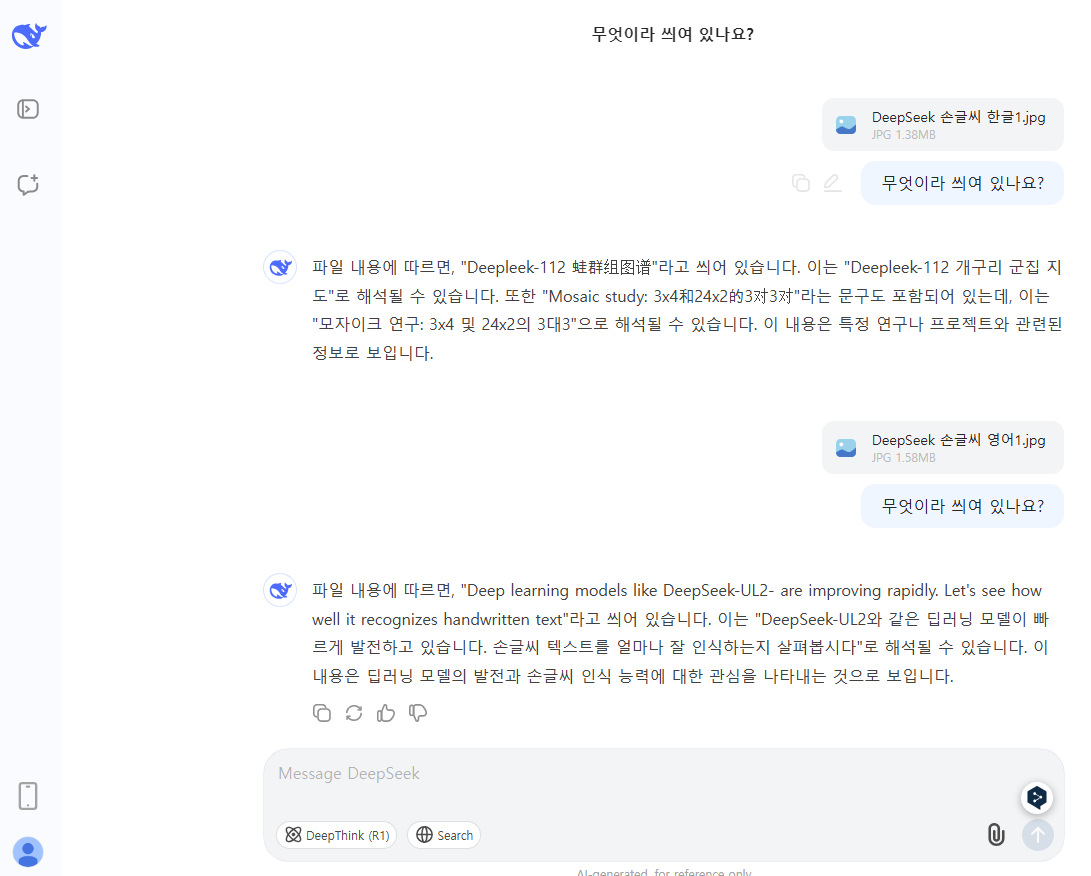
(1) DeepSeek V3 실습
- 영문과 한글
- 한글은 실습일 현재 (2025.2월) 제대로 되지 않고 있음
- 영문의 경우: 상기 DeepSeek-VL2 와 비교할 때 거의 동일함. (단, 이 실습에서 재미있는 것은 "VL2"라고 씌여 있는 것을 DeepSeek-VL2 에서는 정확히 읽고 있으나 DeepSeek V3는 "UL2"라고 되어 있네요.)
(2) ChatGPT 4o
- 영문
- 한글
6. 동영상
- YouTube
www.youtube.com
'AI 최신 동향 및 이슈' 카테고리의 다른 글
| [논문분석] DeepSeek-R1: 강화 학습 활용한 LLM의 추론 능력 향상 연구 분석 (0) | 2025.01.29 |
|---|---|
| 딥시크(DeepSeek)의 등장, 기술 시장의 판도를 다시 그리다(2025.1) (2) | 2025.01.28 |



